
Als je met SEO bezig bent hoor je vaak termen als indexeren, crawlen en crawlbudget. Maar wat betekenen die precies en waarom zijn ze zo belangrijk voor jouw vindbaarheid in Google? Het antwoord is simpel: Als Google jouw website niet goed kan crawlen, kan hij je pagina’s ook niet indexeren of tonen in de zoekresultaten. Crawlen is dus de eerste stap naar online zichtbaarheid. In deze uitgebreide blog bespreken we het volgende:
- Wat is crawlen?
- Waarom is crawlen belangrijk?
- Hoe werkt crawlen technisch gezien?
- Wat is het crawlbudget?
- Waaruit bestaat het crawlbudget?
- Wanneer gaat je crawlbudget verloren?
- Veelvoorkomende oorzaken crawlverlies
- 7x hoe jij jouw crawlbudget kan verbeteren
- Hoe controleer je of Google jouw website goed crawlt?
Wat is crawlen?
Crawlen is de eerste stap in het proces waarmee zoekmachines zoals Google jouw website ontdekken en begrijpen. Wanneer je een nieuwe pagina publiceert, verschijnt die niet automatisch in de zoekresultaten. Eerst moet Google die pagina vinden en dat doet het met behulp van digitale robots, ook wel Googlebots genoemd.
Deze robots verkennen het web dag en nacht. Ze bezoeken miljarden websites, volgen interne én externe links, en verzamelen gegevens over de inhoud, structuur en techniek van elke pagina. Met andere woorden: crawlen is hoe zoekmachines leren wat er op het internet staat en hoe alles met elkaar verbonden is.
Je kunt het vergelijken met een bibliothecaris die nieuwe boeken binnenkrijgt. Hij bekijkt de titel, leest de inhoudsopgave en bladert door het boek om te bepalen waar het over gaat en waar het thuishoort in de bibliotheek. Zo werkt het ook met Google: het probeert te begrijpen waar jouw website over gaat, zodat het die op de juiste plek in de “digitale bibliotheek” kan zetten: de zoekresultaten.
Concreet verloopt het proces van crawlen in vier stappen:
- De Googlebot bezoekt je website. Dit kan via een link op een andere site, via je sitemap of via eerdere bezoeken van de crawler. De bot leest de code en inhoud van je pagina’s. Daarbij kijkt hij niet alleen naar tekst, maar ook naar koppen, afbeeldingen, metadata en technische elementen zoals titeltags of canonical-links.
- Hij volgt links om nieuwe pagina’s te ontdekken. Zowel interne links (binnen je eigen site) als externe links helpen Google om de structuur en relevantie te begrijpen.
- Hij stuurt al die informatie naar Google’s index. Daar wordt alles geanalyseerd en opgeslagen, zodat jouw pagina kan worden vergeleken met miljoenen andere resultaten.
- Pas na het crawlen kan Google je website indexeren, oftewel opnemen in zijn zoekdatabase. Als een pagina niet wordt gecrawld, zal hij dus ook nooit in de zoekresultaten verschijnen, hoe goed de inhoud ook is.
Kort samengevat: Crawlen is hoe zoekmachines jouw website “lezen”. Zonder crawlen geen indexatie en zonder indexatie geen vindbaarheid.
Waarom is crawlen belangrijk?
Crawlen is letterlijk de eerste stap in SEO. Als Google jouw website niet kan crawlen, kan hij je pagina’s niet indexeren en dus ook niet laten verschijnen in de zoekresultaten. Dat betekent dat al het werk dat je in je content, techniek of linkbuilding stopt, niet wordt gezien. Zelfs de beste content, een snelle website of sterke backlinks hebben weinig effect als Google jouw site niet goed kan doorzoeken. Crawlen vormt de basis waarop al je SEO-inspanningen rusten.
Daarom is het belangrijk dat Google jouw website:
- Goed kan vinden via interne links en een duidelijke sitemap
- Snel kan lezen dankzij een technisch gezonde en snelle site
- Efficiënt kan begrijpen met een logische structuur en relevante inhoud
Een goed crawlproces betekent dat Google:
- Al je belangrijke pagina’s ontdekt
- Ze op de juiste manier beoordeelt
- Regelmatig terugkeert om nieuwe of aangepaste content te verwerken
Een slecht crawlproces heeft het tegenovergestelde effect. In dat geval:
- Slaat Google belangrijke pagina’s over
- Blijft verouderde informatie zichtbaar
- Wordt je website mogelijk gezien als traag of onduidelijk
Een goed crawlproces zorgt ervoor dat jouw website zichtbaar, actueel en betrouwbaar blijft. Het is de onzichtbare motor achter duurzame vindbaarheid in zoekmachines.
Hoe werkt crawlen technisch gezien?
Crawlen gebeurt niet één keer, maar voortdurend. Google heeft duizenden zogenoemde Googlebots die dag en nacht het internet afspeuren op zoek naar nieuwe en gewijzigde pagina’s. Elke seconde worden miljoenen websites gecontroleerd, geüpdatet en opnieuw beoordeeld. Dit proces vormt de basis van hoe zoekmachines het web begrijpen. Het proces verloopt in drie stappen:
- Ontdekken
Voordat Google iets kan crawlen, moet het eerst weten dat jouw pagina bestaat. Nieuwe URL’s worden op verschillende manieren ontdekt, bijvoorbeeld via:
- Links op andere websites (backlinks)
- Interne links binnen je eigen site
- Je sitemap.xml, waarin je overzicht geeft van al je pagina’s
- Of via handmatige toevoeging in Google Search Console
Hoe beter je website is verbonden – intern én extern – hoe sneller Google jouw nieuwe content zal vinden. Een pagina die nergens naartoe linkt, is voor Google vrijwel onzichtbaar.
- Crawlen
Zodra de Googlebot jouw URL heeft ontdekt, bezoekt hij de pagina om te lezen wat er precies op staat. Hij bekijkt:
- De HTML-code en structuur van de pagina (koppen, tekst, links)
- De meta-tags, zoals noindex (om pagina’s uit te sluiten) of canonical (om duplicaten te herkennen)
- De aanwezige afbeeldingen en scripts, voor zover de toegang niet is geblokkeerd in het bestand robots.txt
Tijdens het crawlen beoordeelt Google of de pagina goed laadt, technisch in orde is, en waardevolle inhoud bevat. Pagina’s met fouten, trage laadtijden of dubbele inhoud krijgen vaak een lagere prioriteit.
- Indexeren
Na het crawlen wordt de verzamelde informatie doorgestuurd naar Google’s enorme database: de index. Daar wordt je pagina geanalyseerd en vergeleken met miljoenen andere resultaten. Google bepaalt vervolgens waar de pagina over gaat, voor welke zoekopdrachten hij relevant is en hoe hoog hij mogelijk moet ranken.
Belangrijk: een pagina kan pas in de zoekresultaten verschijnen nadat hij succesvol is gecrawld én geïndexeerd. Is de toegang geblokkeerd of bevat de pagina te veel fouten? Dan zal Google die overslaan, wat direct invloed heeft op je zichtbaarheid.
Wat is het crawlbudget?
Nu je weet wat crawlen is, komen we bij een term die vaak wordt vergeten, maar belangrijk is voor SEO: het crawlbudget. Het crawlbudget bepaalt hoeveel pagina’s van jouw website Google per dag (of per periode) bezoekt en verwerkt. Elke website – groot of klein – heeft een eigen crawlbudget, dat afhangt van de technische gezondheid, populariteit en updatesnelheid van de site.
Googlebot kan namelijk niet onbeperkt tijd besteden aan elke website op het internet. Het heeft letterlijk een wereldwijd schema waarin het moet bepalen welke sites prioriteit krijgen. Grote, populaire websites zoals nieuwsplatforms worden dagelijks of zelfs elk uur gecrawld. Kleinere websites worden minder vaak bezocht, soms maar eens per paar dagen of weken.
Een hoog crawlbudget is gunstig, want dat betekent dat Google meer pagina’s van je site kan controleren, bijwerken en indexeren. Een laag crawlbudget kan ervoor zorgen dat:
- Nieuwe pagina’s traag worden gevonden
- Verouderde content lang in de index blijft staan
- Belangrijke wijzigingen (zoals redirects of nieuwe teksten) niet snel worden verwerkt
Google baseert het crawlbudget vooral op twee factoren:
- Crawlcapaciteit: Hoe snel en stabiel je server reageert. Als je website traag is of foutmeldingen geeft, verlaagt Google automatisch het aantal crawlverzoeken.
- Crawlbehoefte: Hoeveel nieuwe of gewijzigde content jouw site heeft. Als je regelmatig updates plaatst, ziet Google dat als een signaal om vaker terug te komen.
Het crawlbudget is als de tijd die Google aan jouw site besteedt. Hoe gezonder, sneller en relevanter je website is, hoe groter de kans dat Google die tijd optimaal benut.
Waaruit bestaat het crawlbudget?
Google bepaalt jouw crawlbudget op basis van twee belangrijke factoren: de crawlcapaciteit en de crawlbehoefte. Samen bepalen ze hoeveel aandacht Google aan jouw website besteedt en hoe vaak jouw pagina’s opnieuw worden bekeken.
- Crawlcapaciteit (crawl rate limit)
De crawlcapaciteit – ook wel crawl rate limit genoemd – is de maximale snelheid waarmee Google jouw website wil crawlen zonder je server te overbelasten. Elke website draait op een server met beperkte capaciteit. Wanneer Google merkt dat jouw site traag reageert, veel foutmeldingen geeft of tijdelijk onbereikbaar is, verlaagt het automatisch de crawlrate. Dat betekent dat Googlebot minder pagina’s per seconde bezoekt, om te voorkomen dat de server nog zwaarder belast wordt. Een snelle, stabiele website daarentegen zorgt voor vertrouwen. Als je hosting goed presteert en je site foutloos reageert, verhoogt Google geleidelijk de crawlcapaciteit. Zo kunnen er meer pagina’s per dag worden gescand.
Kort gezegd:
- Snelle, stabiele servers = meer crawls
- Trage, onbetrouwbare servers = minder crawls
Een slechte hosting of trage laadtijd kan er dus indirect voor zorgen dat belangrijke pagina’s langer onopgemerkt blijven, wat je vindbaarheid vertraagt.
- Crawlbehoefte (crawl demand)
De crawlbehoefte – of crawl demand – bepaalt hoe interessant jouw website is voor Google om te bezoeken. Googlebot wil zijn tijd efficiënt besteden en richt zich vooral op websites die actief en waardevol zijn. Pagina’s die vaak bezocht worden, waardevolle inhoud bieden of regelmatig worden bijgewerkt, krijgen prioriteit. Denk aan:
- Veelgelezen blogs of actuele nieuwsartikelen
- Productpagina’s met nieuwe informatie of voorraadupdates
- Dynamische sites waar content continu verandert
Pagina’s die daarentegen oud, inactief of niet relevant lijken, krijgen minder crawlbudget. Dat betekent niet dat ze verdwijnen uit de index, maar wel dat Google ze minder vaak controleert of bijwerkt. Kortom: hoe sneller, relevanter en actiever je website, hoe meer crawlbudget Google eraan besteedt. Een technisch gezonde en regelmatig vernieuwde site wordt simpelweg vaker bezocht – en dat is precies wat je wilt als je goed zichtbaar wilt blijven.
Wanneer gaat je Crawlbudget verloren?
Veel websites verliezen ongemerkt een groot deel van hun crawlbudget. Dat gebeurt wanneer Google tijd besteedt aan onbelangrijke, dubbele of technisch problematische pagina’s in plaats van aan de pagina’s die er echt toe doen. Je kunt het zien als een postbode die elke dag dezelfde lege brievenbus bezoekt, terwijl de echte belangrijke adressen worden overgeslagen. Google heeft maar een beperkte hoeveelheid tijd om jouw site te verkennen en die wil je zo efficiënt mogelijk benutten.
Veelvoorkomende oorzaken van crawlbudgetverlies
- Dubbele URL’s: Een van de grootste boosdoeners zijn dubbele of variabele URL’s. Voor Google lijken dit allemaal aparte pagina’s, terwijl de inhoud identiek is. Het gevolg: verspild crawlbudget én kans op duplicate content. Dat gebeurt bijvoorbeeld wanneer:
- Je webshop meerdere filters of sorteeropties gebruikt (zoals ?kleur=rood of ?maat=m)
- Je gebruikmaakt van UTM-tracking of campagneparameters
- Wanneer dezelfde pagina via meerdere URL’s bereikbaar is (met en zonder www, of met /index.php)
- Onnodige of irrelevante pagina’s: Veel websites laten Google pagina’s crawlen die eigenlijk niet relevant zijn voor bezoekers of zoekresultaten. Deze pagina’s dragen niet bij aan je SEO-prestaties, maar verbruiken wel waardevolle crawlcapaciteit. Denk daarbij aan pagina’s zoals:
- Login- of registratiepagina’s
- Test- of stagingomgevingen
- Interne zoekresultatenpagina’s
- Maandelijkse archieven in blogs
- Trage laadtijden: Wanneer je website traag reageert of regelmatig foutmeldingen geeft (zoals 500-errors of time-outs), vertraagt Google automatisch de snelheid van het crawlen. Een trage site betekent dat Google in dezelfde tijd minder pagina’s kan verwerken, waardoor belangrijke content minder vaak of zelfs helemaal niet meer wordt bezocht.
7x hoe jij jouw crawlbudget kan verbeteren
Het goede nieuws: je kunt zelf veel doen om jouw crawlbudget optimaal te benutten. Het doel is simpel, namelijk zorgen dat Google zijn tijd besteedt aan de pagina’s die er écht toe doen. Het gaat dan ook om jouw belangrijkste, actuele en waardevolle content. Hieronder vind je de belangrijkste optimalisaties die direct effect hebben op hoe efficiënt Google jouw website crawlt.
1. Maak een duidelijke sitemap
Een sitemap is letterlijk de routekaart van jouw website. Het vertelt Google welke pagina’s belangrijk zijn, hoe ze met elkaar verbonden zijn en wanneer ze voor het laatst zijn bijgewerkt. Zo weet Googlebot precies waar hij moet beginnen en welke pagina’s prioriteit hebben. Gebruik een SEO-plugin zoals Yoast SEO of RankMath (voor WordPress) om automatisch een sitemap.xml te genereren. Vervolgens:
- Controleer of de belangrijkste pagina’s erin staan (zoals home, diensten, blog en contact)
- Sluit onbelangrijke pagina’s uit (zoals testpagina’s, archieven of loginomgevingen)
- Dien de sitemap in via Google Search Console → Sitemaps → voeg je URL toe (bijv. /sitemap.xml)
Een actuele sitemap helpt Google om sneller nieuwe of gewijzigde content te ontdekken en indexeren.
2. Gebruik interne links
Googlebot ontdekt nieuwe pagina’s door links te volgen, net als een gebruiker dat doet. Zonder interne links kan een pagina “verstopt” raken, waardoor Google hem minder snel of zelfs helemaal niet crawlt. Zorg dus dat je belangrijkste pagina’s:
- Vanaf de homepage bereikbaar zijn,
- In het hoofdmenu of de footer staan,
- En regelmatig worden gelinkt in blogs, nieuwsberichten of productpagina’s.
Tip: gebruik duidelijke ankerteksten die beschrijven waar de link naartoe gaat. Dus: “Bekijk onze SEO-training” in plaats van “klik hier”. Dat helpt niet alleen bezoekers, maar ook Google om de inhoud te begrijpen.
3. Verwijder of blokkeer onbelangrijke pagina’s
Niet elke pagina hoeft in Google te verschijnen. Sommige pagina’s hebben een puur functioneel doel, zoals een bedankpagina of interne zoekresultaten, en verbruiken onnodig crawlbudget. Gebruik daarom het noindex-attribuut (beschikbaar in SEO-plugins als Yoast of RankMath) om deze pagina’s uit te sluiten van indexatie. Voorbeelden van pagina’s die je beter kunt uitsluiten:
- Bedankpagina’s na een formulier,
- Interne zoekpagina’s (/zoeken/?q=),
- Test- of conceptpagina’s,
- Loginomgevingen of gebruikersprofielen.
Zo richt Google zich alleen op de content die écht bijdraagt aan jouw vindbaarheid.
4. Voorkom 404-fouten en overbodige redirects
Elke foutmelding of redirect kost tijd en dus crawlcapaciteit. Wanneer Google te vaak op een dood spoor uitkomt (zoals een verwijderde pagina of een lange keten van redirects), vermindert dat de efficiëntie van het crawlen. Controleer dit regelmatig met:
- Google Search Console → Rapport Pagina’s / Niet-geïndexeerd
- Screaming Frog SEO Spider → om 404-pagina’s en redirect-loops te vinden
Zo los je het op:
- Maak 301-redirects aan naar relevante pagina’s (niet naar de homepage)
- Verwijder overbodige redirects of oude URL’s
- Houd de interne links up-to-date, zodat Google altijd directe routes vindt
5. Verhoog je websitesnelheid
Je website snelheid is zó belangrijk. Niet alleen voor gebruikers, maar ook voor het crawlen. Hoe sneller je site reageert, hoe meer pagina’s Google binnen hetzelfde tijdsbestek kan scannen. Gebruik tools zoals:
- Google PageSpeed Insights (lees hier over de Core Web Vitals)
- GTmetrix
- Lighthouse (Chrome DevTools)
Optimaliseer vervolgens op drie punten:
- Afbeeldingen → comprimeer ze tot max. 200–300 KB en gebruik het bestandsformaat .webp.
- Caching → gebruik een plugin als WP Rocket of LiteSpeed Cache.
- Hosting → kies een betrouwbare partij met SSD-opslag en HTTP/2-ondersteuning.
Een snellere site = meer crawls = snellere indexatie.
6. Update regelmatig je content
Googlebot houdt van activiteit. Pagina’s die regelmatig worden bijgewerkt of aangevuld, worden automatisch vaker gecrawld. Wat kun je doen?
- Publiceer regelmatig nieuwe blogs of nieuwsartikelen
- Werk bestaande pagina’s bij met actuele voorbeelden, cijfers of links
- Voeg interne verwijzingen toe naar nieuwe content
Zo geef je Google het signaal dat jouw site levendig, relevant en betrouwbaar is én dat loont in crawlbudget én ranking.
7. Gebruik de robots.txt slim
Het bestand robots.txt vertelt zoekmachines welke delen van je website ze mogen overslaan. Zo voorkom je dat Google tijd verspilt aan pagina’s die niet belangrijk zijn voor SEO. Voorbeeld van een goed ingesteld bestand:
User-agent: *
Disallow: /wp-admin/
Disallow: /zoekresultaten/
Allow: /wp-content/uploads/
Sitemap: https://www.jouwwebsite.nl/sitemap.xml
Let op: Blokkeer nooit per ongeluk pagina’s die je wél in Google wilt laten zien. Controleer dit regelmatig, vooral na technische aanpassingen of een website-update.
Hoe controleer je of Google jouw site goed crawlt?
Gebruik hiervoor vooral Google Search Console. Ga naar: Instellingen → Crawlenstatistieken.
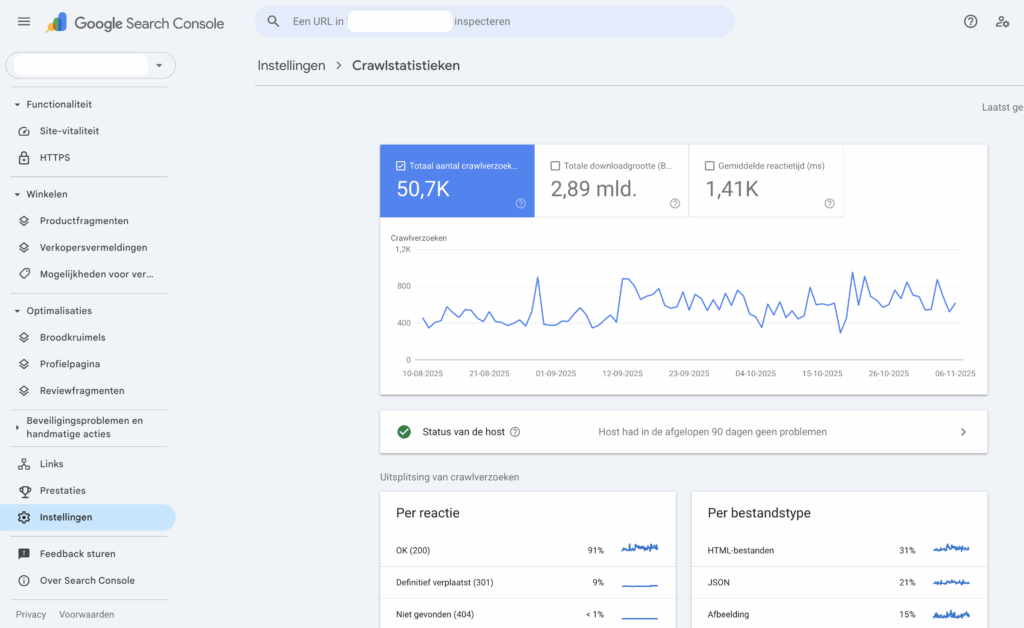
Hier zie je:
- Hoeveel crawlverzoeken er zijn gedaan
- Welke pagina’s of secties het meest bezocht worden
- Hoe snel je server reageerde
- Of er fouten of blokkades zijn
Zie je plotseling een daling in het aantal crawls of toenemende fouten? Dan is dat vaak een teken dat Google moeite heeft om je site te bereiken. Het is een belangrijk signaal om direct te optimaliseren.
Crawlen in een notendop
Crawlen is de ruggengraat van SEO. Zonder goed crawlproces blijft je content onzichtbaar, hoe goed die ook is. Door te begrijpen wat crawlen is, hoe het crawlbudget werkt en hoe je het optimaliseert, zorg je dat Google jouw site volledig en efficiënt doorzoekt. Wie zijn website toegankelijk maakt voor crawlers, maakt zich zichtbaar voor klanten.



